


Zuletzt aktualisiert am 15. Mai 2025.
Einen Storagenode auf einem Synology-NAS installieren und mit freiem Speicher Geld verdienen.
Der Gedanke liegt Nahe: Auf dieser Welt wird viel Geld für Onlinespeicher, sog. Cloudspeicher ausgegeben. Riesige Rechenzentren werden einzig und allein betrieben, um immense Speichermengen bereitzuhalten.
Auf der anderen Seite werden
Ein Storj-Node auf einem Synology-NAS
In diesem Tutorial zeige ich Dir, wie Du auf Deinem Synology NAS einen sog. Storagenode des Storj-Projekts installieren kannst.
Voraussetzungen und Grundanforderungen
Storj gibt ein paar Anforderungen vor, die zwingend zum Betrieb eines Storagenodes auf einem Synology NAS erfüllt sein müssen:
- Aktivierter SSH-Zugang auf dem NAS
- Dockerfähiges Synology NAS (afaik alle NAS mit Intel Prozessor) und installiertes Docker-Paket.
- Ein Ethereum-Wallet (mit Unterstützung für ERC20 Token).
Wieso benötige ich ein Ethereum Wallet?
Ethereum ist eine sog. Kryptowährung, die auf einer Blockchain basiert. Neben Ethereum können Smart-Contracts sowie ERC20 Token als Payload gespeichert werden.
Storj errechnet die Vergütung in US-Dollar, zahlt diese Vergütung aber in einer eigenen Kryptowährung, den sog. “Storj-Token” (ein ERC20 Token) aus. Auf dem Wallet müssen sich für Storj-Auszwhalugnekeine Ethereum-Coins befinden.
Schritt 1: Der Authorization Token
Um einen Node zu erstellen und diesen im Netzwerk anzumelden, musst Du Dir einen Authorization Token zuschicken lassen. Das geht über direkt über folgende URL: https://www.storj.io/host-a-node
Hier müssen nun kurz die oben bereits genannten Anforderungen angehakt werden und eine gültige E-Mail-Adresse angegeben werden. Im Anschluss erhält man (sofern aktuell neue Nodes zugelassen werden, sonst landet man auf einer Warteliste) per E-Mail einen Authorization Token.
Wieso braucht man einen Authorization Token?
Das Storj-Projekt gibt es schon länger (die aktuelle Version ist die v3) und das Team hat aus den Erfahrungen des Vorgängers (v2) gelernt. So kann Storj über die Vergabe der Authorization-Tokens steuern, wie viele (neue) Nodes es im Netzwerk gibt und damit in etwa, wie viel Speicher im Angebot ist. Es kann so ein stabiles Netzwerk aufgebaut werden, wo Angebot und Nachfrage zumindest nicht diametral auseinander gehen.
Schritt 2: Identität erstellen
Um als Storagenode im Netzwerk dabei zu sein, muss eine individuelle Identität erstellt werden. Diese wird mit Hilfe des Authorization Token errechnet.
Zunächst muss nun das Identity-Binary heruntergeladen werden:
curl -L https://github.com/storj/storj/releases/latest/download/identity_linux_amd64.zip -o identity_linux_amd64.zipTipp: Ich erstelle immer direkt ein Verzeichnis für jeden Storagenode, hier lade ich auch das Identity-Binary herein.
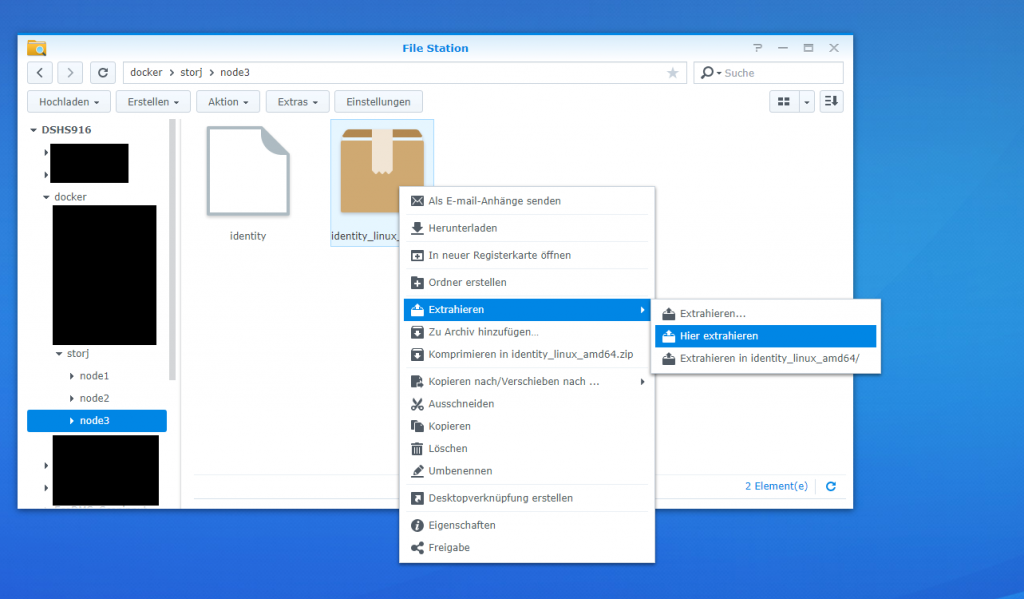
Danach muss das heruntergeladene zip-File entpackt werden. Die Doku von Storj greift hier auf “unzip” auf der Konsole zurück. Das funktioniert auf dem NAS mit DSM 6.x nicht. Wir können das zip-Archiv aber einfach über die DSM-Oberfläche entpacken.
Jetzt müssen wir das entpackte Binary noch ausführbar machen. Dafür geben wir dem File über die Konsole mittels “chmod” das entsprechende Flag:
chmod +x identityAnschließen verschieben wir das Binary in das bin-Verzeichnis des Systems, damit es simple über die Konsole aufgerufen werden kann und dem NAS bekannt ist:
sudo mv identity /usr/local/bin/identityErstellen der Identität
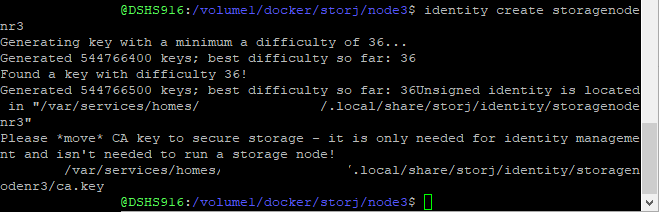
Dieser letzte Schritt ist der entscheidende – und er ist sehr rechenlastig und benötigt daher je nach Leistung des NAS eine gewisse Weile (teilweise sehr viele Stunden!). Ich lasse den Prozess immer über Nacht laufen.
identity create my_storagenode_name
Wenn der Prozess abgeschlossen ist, sieht das so aus:
Schritt 3: Identität authorisieren/anmelden
Mit diesem Schritt wird Dein Node im Storj-Netzwerk angemeldet.
Achtung: Ab hier läuft der Zähler für die Downtime des Nodes.
identity authorize my_storagenode_name <email:characterstring>Tipp: Es ist durchaus sinnvoll, die generierte Identität an einem Ort der eigenen Wahl zu sichern. So ist es möglich, im falle eines Falles einen Node später mal umzuziehen.
Ich habe mir dazu auf einem anderen Raid-Volumen der Synology ein Verzeichnis erstellt, wo ich gesammelt die Identitäten meiner Storagenodes speichere.
Schritt 4: Datenverzeichnis erstellen
Während ich die Konfiguration meiner Storagenodes zentral auf einem Volumen in einem Verzeichnis mit einem Unterverzeichnis für jeden Node verwalte (bei mir nach dem Schema docker/storj/node1 usw.) muss das Datenverzeichnis für den Node logischerweise immer auf der Festplatte bzw. auf dem Volume liegen, wo letztlich auch die Daten gespeichert werden sollen.
Dafür erstellt man über das DSM, also die Weboberfläche des Synology NAS, zunächst ein neues Volume auf der für den Node vorgesehenen Festplatte und erstellt dort dann einen gemeinsamen Ordner und darin dann ein Datenverzeichnis. Ich nenne benenne das gemeinsame Verzeichnis schlicht immer “StoragenodeX” (X steht für die Nummer des Nodes ; 1,2,3 usw.). Das Datenverzeichnis selbst nenne ich immer “data”.
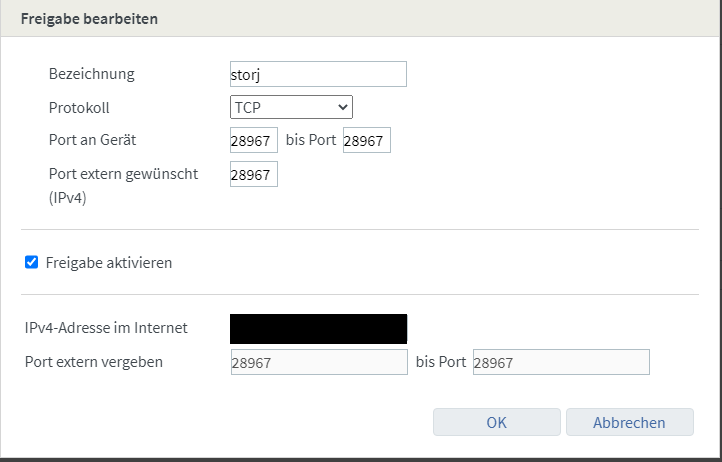
Schritt 5: Portfreigabe
Damit Daten aus dem Netzwerk auf dem Node gespeichert werden können und Daten abgerufen werden können, muss der Node aus dem Internet erreichbar sein. Dafür müssen wir auf deinem Router einen Port freigeben und an das NAS weiterleiten.
Es handelt sich dabei in der Standardkonfiguration um Port 28967 über das TCP-Protokoll.
Schritt 6: Aktuelles Docker-Image für Storagenode laden
Um einen Docker-Container mit einem Storj-Storagenode auf einem Synology-NAS laufen zu lassen brauchen wir natürlich noch das Docker-Image für den entsprechenden Node. Dieses können wir uns über die DSM-Oberfläche vom Docker-Hub laden, oder alternativ aus Bequemlichkeit die Konsole nutzen:
docker pull storjlabs/storagenode:latestAchtung: Seit kurzem ist das Storj-Netzwerk im Produktivbetrieb, es ist daher notwendig den “latest” Tag beim Docker-Image zu verwenden.
Schritt 7: Storagenode starten!
Update Februar 2021: Seit kurzem ist es notwendig, vor dem eigentlichen Start des Storagenode-Containers, den selben Container mit dem “Setup”-Parameter zu starten. Diesen Schritt musst du nur einmal durchführen.
Im Rahmen dieses Setups wird überprüft, ob die gemäß config gemounteten Verzeichnisse auch wirklich verfügbar und beschreibbar sind.
docker run --rm -e SETUP="true" --mount type=bind,source="<identity-dir>",destination=/app/identity --mount type=bind,source="<storage-dir>",destination=/app/config --name storagenode storjlabs/storagenode:latestDu musst hier lediglich folgende Variablen ersetzen:
| Variable | Bedeutung |
| <identity-dir> | Der Pfad zum Verzeichnis, in dem die Identity liegt |
| <storage-dir> | Der Pfad zum Storage-Verzeichnis (Wo die Daten gespeichert werden sollen) |
Update Februar 2022: Noch einfacher ist es einfach im selben Verzeiochnis, wo man seine docker-compose.yml-datei liegen hat, den folgenden Befehl zu starten. Das Setup wird dann durchgeführt:
docker-compose run --rm --no-deps -e SETUP=true storagenodeDanach ist das Starten des Nodes ist über einen Befehl auf der Konsole möglich:
docker run -d --restart unless-stopped --stop-timeout 300 \
-p 28967:28967 \
-p 127.0.0.1:14002:14002 \
-e WALLET="0xXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" \
-e EMAIL="user@example.com" \
-e ADDRESS="domain.ddns.net:28967" \
-e STORAGE="2TB" \
--mount type=bind,source="<identity-dir>",destination=/app/identity \
--mount type=bind,source="<storage-dir>",destination=/app/config \
--name storagenode storjlabs/storagenode:latestDie folgenden Parameter müssen entsprechend Deiner Konfiguration angepasst werden:
| Parameter | Bedeutung |
| -p | Die Ports, über die der Storagenode kommuniziert. Der erste Port gibt den Port außerhalb des Containers an, also den Port, der freigegeben werden muss. Der zweite Port ist dabei der interne Port im Container, auf den gemapped wird. |
| -p | Der zweite -p Parameter gibt an unter welcher IP und welchem Port das Storga-Node-Dashboard aufrufbar ist. Diesen Port würde ich nicht nach außen freigeben. |
| -e | Hier muss die Adresse Deiner Ethereum-Wallet angegeben werden. |
| -e | Der zweite -e Parameter (EMAIL) enthält Deine E-Mail-Adresse unter der Du z.B. erreichbar bist, wenn es Probleme mit Deinem Node gibt. |
| -e | Der dritte -e Parameter (ADDRESS) muss die öffentlich erreichbare Adresse Deines Noodes enthalten. Das kann eine (feste!) IP, eine Domain oder eine dyndns-Adresse sein. |
| -e | Der vierte -e Parameter (STORAGE) enthält die Angabe, wie viel Speicher auf Deinem Node zur Verfügung stehen. Achtung: Diese Angabe muss wahrheitsgemäß sein, gibst Du mehr Speicher an, als zur Verfügung steht, gehen Schreibvorgänge “ins Leere”, was in Datenverlust auf Deinem Node und der Disqualifizierung Deines Node resultiert. Tipp: Es sollten unbedingt 10% des eigentlich verfügbaren Speichers als “Reserve” für temporäre- und Metadaten vorgehalten werden. Bei 3TB Speicher solltest Du hier also maximal 2,7TB angeben. |
| identity-dir | Hier muss der Verzeichnispfad angegeben werden, in dem sich die zu Anfang erzeugte Identity befindet. |
| storage-dir | Hier muss der Verzeichnispfad zum Datenverzeichnis (siehe Schritt 4) angegeben werden. |
Ich bin aber Verfechter einer in meinen Augen einfacheren Methode: Ich nutze eine docker-compose.yml-Datei.
So sieht (m)eine docker-compose.yml für einen Storagenode aus:
# based on https://documentation.storj.io/setup/cli/storage-node
# and based on https://www.jamescoyle.net/how-to/docker-compose-files/3219-storj-storage-node-docker-compose-file
# check the yml-code here: http://yaml-online-parser.appspot.com/
version: "3.2"
services:
storagenode:
container_name: storagenode1
image: storjlabs/storagenode:latest
restart: unless-stopped
ports:
- "28967:28967"
- "14002:14002"
volumes:
- type: bind
source: /volume1/docker/storj/node2/identity
target: /app/identity
- type: bind
source: /volume2/storj/data
target: /app/config
environment:
- WALLET=0xXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
- EMAIL=user@example.com
- ADDRESS=meinedomain.de:28967
- BANDWIDTH=30TB
- STORAGE=1.6TB
- STORJ_LOG_LEVEL=infoDie Inhalte bzw. Parameter decken sich in erster Linie mit denen aus dem direkten Kommando.
Starten kann man den Node dann entsprechend mit dem Kommando
docker-compose up -dim jeweiligen Verzeichnis, in dem die docker-compose.yml liegt.
Was kann ich mit Storagenodes verdienen?
Die Einnahmen
Eine wichtige Frage und darauf zunächst die klare Antwort: Mit Storagenodes wird man nicht reich. Es geht in erster Linie um den Gedanken eines verteilten Storagenetzwerkes, den man unterstützen möchte. Natürlich ist es schön, wenn dabei nach Abzug von Stromkosten und Co. noch ein wenig übrig bleibt 😉
Ohnehin gilt – auch offiziell – die Maßgabe, dass überschüssiger Speicher auf ohnehin 24/7 laufenden Geräten genutzt werden sollte. Wie es eben auf einem NAS oft der Fall ist 😉
Es gab zu Beginn einen offiziellen Rechner, der den möglichen Verdienst mit einem Storagenode je nach Auslastung skizzieren sollte. Meiner Erfahrung nach ist dieser Rechner mehr als optimistisch gewesen und entsprach in keiner Weise den (aktuellen) Usage-Pattern im Storj-Netzwerk. Die dortigen Werte sind mMn nicht zu erreichen gewesen 😉
Edit August 2022: Mittlerweile gibt es den offiziellen Rechner nicht mehr. Dafür gibt es von der Community gepflegte Rechner, die wesentlich aussagekräftigere Ergebnisse liefern. Zum Einen sei dabei der “Realistic Earnings Estimator” in Form eines google Sheets genannt. Aber natürlich auch der Online-Calculator auf dieser Seite.
Ich habe euch mal meine aktuellen Werte aufgelistet (in Klammern steht der zurückbehaltene Betrag, der sog. Heldback):
| Monat | Node | Node2 | Node3 | Node4 | Auszahlung Storj | |
| Januar 2020 | 36,07$ (27,05$ Heldback) | – | – | 66 Storj | ||
| Februar 2020 | 27,01$ (20,26$ Heldback) | – | – | 54 Storj | ||
| März 2020 | 17,46$ (11,93$ Heldback) | – | – | 59 Storj | ||
| April 2020 | 5,11$ (3,22$ Heldback) | – | – | 17 Storj | ||
| Mai 2020 | 3,66$ (1,83$ Heldback) | 2,12$ (1,58$ Heldback) | – | 16 Storj | ||
| Ab hier summierte Auszahlungen1 | ||||||
| Juni 2020 | 4,02$ (1,82$ Heldback) | 4,13$ (3,10$ Heldback) | 0.17$ (0,13$ Heldback) | – | 20 Storj | |
| Juli 2020 | 12,00$ (5,10$ Heldback) | disqualified2 | 5,37$ (4,03$ Heldback) | – | 44 Storj | |
| August 2020 | 17,65$ (5,20$ Heldback) | – | 6,99$ (5,24$ Heldback) | 1,76$ (1,32$ Heldback) | 143 Storj3 | |
| September 2020 | – | – | – | – | 38 Storj | |
| Oktober 2020 | – | – | – | – | 63 Storj | |
| November 2020 | – | – | – | – | 72 Storj | |
| Dezember 2020 | – | – | – | – | –4 | |
| Januar 2021 | – | – | – | – | –4 |
Die obige Statistik habe ich seit Ende 2020 nicht mehr weiter geführt.
Die aktuellen Statistiken zu meinen Storagenodes findest du hier.
Fußnoten
1: Das Storj-Projekt bezahlt die Storagenodebetreiber in sog. Storj-Token. Diese Storj-Token ist im Prinzip eine Kryptowährung/ein Kryptocoin. Es handelt sich jedoch um einen sog. “ERC-20-Token”. Das heißt, der Token nutzt die Ethereum-Blockchain und keine eigene Blockchain. Für jede Auszahlung wird daher eine Transaktion auf der Etherum-Blockchain erzeugt. Die Gebühren für diese Transaktionen sind seit Anfang 2020 rapide gestiegen, sodass das Storj-Projekt nun die Auszahlungen an die Storagenodebetreiber in einer Auszahlung pro Betreiber bündelt.
2: Nun hat es leider im Juli 2020 meinen “Node 2” erwischt. Ende Juli ist der Controller der genutzten USB-Festplatte kaputt gegangen. Dadurch ist das Datenverzeichnis geunmounted worden, der Node lief weiter und wurde innerhalb weniger Stunden diusqualifiziert. Dieses Verhalten ist übrigens seit den 1.12er Versionen der Storagenodes behoben: Sobald das Datenverzeichnis nicht mehr gemounted ist, schaltet sich der Node automatisch ab – man hat so die Chance, den node vor einer Disqualification zu retten.
3: Wie kommt es zu dieser überdurchschnittlich hohen Auszahlung im August 2020? Der Satellite stefan-benten wird abgeschaltet (es handelte sich hierbei um einen Satellite, der nur für Tests gedacht gewesen ist). Daher wurde der gesamte Heldback-Betrag hier einmalig ausgezahlt (siehe hier).
4: Für Dezember 2020 und Januar 2021 habe ich bisher keine Auszahlungen erhalten. Weitere Infos dazu: hier.
Update Juni 2020: Ab Juni 2020 werden die Auszahlungen gesammelt für alle Nodes ausgeführt. Trotzdem ist – trotz sinkender Heldbacks und der vollen Auslastung meines “Hauptnodes” eine rapide Verschlechterung des Verdienstes sichtbar.
Das liegt primär daran, dass im Testbetrieb einige Monate die Auszahlungen ver-x-facht worden sind, um die Storagenodebetreiber zu halten. Diese Vervielfachungen des Verdienstes sind seit dem Produktivbetrieb nicht mehr vorhanden.
Update Juli 2020: Es scheint ein Problem mit meinem größten Node (Node1) zu geben, das die rapide gesunkenen Einnahmen erklären könnte. Seit März 2020 wird mir dort der ausgehende Traffic nicht mehr vergütet.
Ich habe das Problem im Storj-Forum gemeldet.
Das erklärt auch, wieso bereits mein viel jüngerer 2. Node im Juni mehr Einnahmen gebracht hat, als mein “alter” Node, der zudem noch mehr Speicher hat und ein Vielfaches an Egress (ausgehendem Traffic).
Update August 2020: Das Problem mit dem nicht bezahlten Upload ist mittlerweile behoben, es handelte sich um ein Problem innerhalb meines Nodes (mehr dazu hier).
Aktuelle Daten und Statistiken zu meinen Nodes
Anbei die aktuelle Auslastung der Bandbreite sowie der aktuell belegte Speicherplatz auf meinen Storagenodes:
Aktuelle Speicherbelegung:

Aktuelle Bandbreite:

*Die Grafiken werden alle 5 Minuten aktualisiert.
Hinweis: Eine Vielzahl weiterer Statistiken und grafischer Auswertungen zu meinen Storagenodes findest Du hier: https://addictedtocode.de/storj/statistiken-zu-meinen-storagenodes/
Die Kosten
Für das Einrichten und den Betrieb eines Storagenodes fallen natürlich kosten an.
Schauen wir uns diese mal im Detail an.
Die Betriebskosten
Die Betriebskosten sind in erster Linie Stromkosten und kosten für einen entsprechenden Breitbandanschluss ans Internet. Wer es ganz genau nimmt, der bezieht vermutlich noch den Verschleiß bzw. den Ausfall von Festplatten und Co mit in die Rechnung.
Ich beschränke mich zunächst rein auf die Stromkosten.
Meine Nodes laufen auf einer Synology Diskstation DS3018xs. Das Gerät ist ausreichend leistungsfähig und verfügt bei mir über 24GB RAM.
Das NAS verbraucht im laufenden Betrieb in meiner Konfiguration gut 70 Watt.
Das entspricht einem Stromverbrauch von ca. 50 kW/h im Monat.
Beim aktuellen Strompreis von durchschnittlich 30 Cent je kW/h sind das immerhin 15€ im Monat.
Betriebskosten Stromverbrauch NAS im Monat:
| Verbrauch kW/h | Preis kW/h | Stromkosten / Monat |
| 50 kW/h | 0,30€ | 15€ |
Der Betrieb eines Storagenodes ist auf vielen – auch kleineren NAS von Synology möglich. Unabdingbar ist aktuell die Docker-Unterstützung.
Wenn wir jetzt ganz kleinlich sind, rechne ich noch die notwendige Breitband-Internetverbindung mit ein. Diese kostet mich für 20MBit Upload-Bandbreite (Kabel) 40€ monatlich.
| Gesamtkosten / Monat Strom | Gesamtkosten im Monat Strom und Internet |
| 15€ | 55€ |
Die Anschaffungskosten
Wenn man nun überlegt, ein NAS extra für den Betrieb von Storagenodes anzuschaffen, dann muss man die Anschaffungskosten mit einbeziehen.
Ich stelle einmal meine Variante gegen einer LowCost-Variante gegenüber.
| Kategorie | Meine Variante | LowCost-Variante |
| NAS | 1400€ (DS3018xs) | 315€ (DS218+) |
| HDDs | 300€ (2*4TB) | 200€ (2*4TB) |
| SSD-Volume für Datenbank* | 250€ (2 * EVO 960 SSD) | – |
| Summe: | 1950€ | 515€ |
Kritik: Wie StorjLabs Vertrauen verspielt
StorjLabs hat im Januar 2021 wenige Tage vor der regulären Auszahlung bekannt gegeben, dass es ab sofort eine Auszahlungsgrenze geben wird und Einnahmen der Storagenodes erst ab einem Betrag X ausgezahlt werden.
“Bekannt gegeben” ist dabei jedoch noch arg beschönigt. Es hat lediglich einen Post im eigenen Forum gegeben. Keine Notification über die Storagenode-Oberfläche. Keine Benachrichtigung per Mail. Begründet wird der Schritt mit den zu diesem Teitpunkt sehr hohen Transaktionskosten im Ethereum-Netzwerk (Der Storj-Token ist ein ERC20-Token auf der Ethereum-Blockchain).
Die Aktuelle Regelung, wann ein Storgaenodebetreiber eine Auszahlung erhält: -> Wenn die durchschnittliche Transaktionsfee im Ethereum-Netzwerk in den letzten 12 Stunden vor der Auszahlung weniger als 25% der gesamten Auszahlungssumme betragen hat. Ein Beispiel: Wenn die Transaktionskosten bei 5$ liegen, musst Du mindestens 20$ Vergütung generiert haben, um eine Auszahlung zu erhalten. Es zählt dabei die Summe der Vergütungen aller unter der jeweiligen Wallet-Adresse laufenden Storagenodes. Erhält der Storagenodebetreiber keine Auszahlung, wird die Vergütung selbstverständlich aggregiert und beim nächsten Zyklus, in dem die Auszahlungsgrenze überschritten wird, ausgezahlt.
Die Begründung ist durchaus nachvollziehbar, das Problem bzw. die Richtung der Steigenden “Gas”-Preise aber seit Langem bekannt. Daher ist Kritik laut geworden, dass Storjs das Thema lange ignoriert habe und sehenden Auges in die aktuelle Situation gelaufen sei und die Folgen dann mit einer “Hau-Ruck”-Aktion auf die Storeganode-Betreiber abwälze.
Natürlich hat sich StorjLabs hier an die eigenen AGB gehalten, die eine Anpassung der Auszahlungsmodalitäten etc. explizit jederzeit erlauben. Trotzdem macht die Art auf mich einen weniger professionellen Eindruck und hat – bei mir jedenfalls – Vertrauen verspielt. Wenn ich nicht bereits seit einiger Zeit dabei wäre, würde bei mir durchaus ein gewisser “SCAM-Verdacht” aufkommen.
Ich werde dem Projekt natürlich trotzdem treu bleiben, möchte aber die Aspekte der unzureichenden Kommunikation und “Hauruck”-Entscheidungen, die für Investitionen alles andere als optimal sind, nicht außen vor lassen.
TL;DR: Anmerkung am Rande
Dadurch, dass ich z.B. meine Auszahlung für Dezember und Januar erst im Februar bekommen werde, werde ich vermutlich – aufgrund des Preisanstiegs der Storj-Token – ca. 30% weniger Tokens erhalten. Anders gesprochen: Hätte ich meine Vergütung wie gewohnt erhalten, hätte ich nun 30% mehr Wert. Das ist insofern in Ordnung (da Storj in Dollar rechnet und nicht im Token-Wert), aber m.M.n. ärgerlich, da die Verzögerung einseitig von Storj in einer Hau-Ruck-Aktion verursacht worden ist.
Unterm Strich: Spannend wenn das NAS ohnehin läuft.
Jetzt geht es ans Eingemachte – ab wann ist ein Storagenodebetrieb überhaupt lohnenswert?
Szenario 1: Das NAS läuft ohnehin
Das NAS läuft ohnehin und verbraucht Strom. Eine Internetverbindung braucht man auch sowieso. Es entstehen also keine zusätzlichen Kosten und der überschüssige Speicher auf dem NAS kann gewinnbringend vermietet werden.
Bereits ab dem ersten Cent kann man die Einnahmen als Gewinn betrachten.
In diesem Szenario lohnt sich ein Storagenode in jedem Fall und sollte in Angriff genommen werden.
Szenario 2: Das NAS läuft ohnehin, Ausbau mit Festplatten
Wenn das NAS ohnehin läuft gilt in Bezug auf Stromverbrauch und Internetanschluss selbiges wie in Szenario 1. Lediglich die Upgrades der Festplatten müssen sich amortisieren.
In diesem Fall lohnt sich ein Storagenode erst nach einiger Zeit, kann aber durchaus gewinnbringend betrieben werden.
Szenario 3: Neuanschaffung sämtlicher Bestandteile
In diesem Szenario wird es schwierig. Rein wirtschaftlich sollte man sich gut überlegen, ob man sämtliche Hardware für Storagenodes neu anschaffen möchte, der break-even dürfte wenn überhaupt erst weit in der Zukunft erreicht werden.
Allerdings gibt es da ja noch den Enthusiasmus für ein tolles Projekt 😉
August 2022: Wieso ich an das Storj-Projekt glaube
Ich bin nun seit einigen Jahren beim Storj-Projekt als “SNO” (Storagenode Operator) dabei. Und ja, ich habe mich über manche Dinge geärgert und es lief nicht immer alles rund.
Aber das Projekt wächst langsam aus den Kinderschuhen heraus. Folgende meine Punkte, wieso ich mehr denn je an das Projekt glaube:
- Storj ist nachhaltig
Für Storj werden keine großen Rechenzentren betrieben. Außerdem muss kein großes (zentrales) Backbone betrieben werden, es wird die Bandbreite der Storagenode-Betreiber aggregiert. - Storj ist sicher(er)!
Zum Einen sind die Daten – auch wenn sie bei fremden Personen auf privaten Festplatten liegen – sicher. Denn die Daten sind verschlüsselt werden beim Upload in viele kleine Segmente zerlegt, die dann von den sog. “Satellites” über viele verschiedene Storagenodes verteilt werden. Ein Node hat dabei nie so viel Datensegmente, dass der Provider Daten einsehen könnte. Die Satellites fungieren gewissermaßen als Inhaltsverzeichnis. Sie wissen, wo welche Teile gespeichert sind, um die Daten wiederherzustellen.
Da die Daten dezentralisiert gespeichert sind, ist die Verfügbarkeit sogar höher, als es bei herkömmlichen Rechenzentren der Fall wäre. - Storj ist günstig
Storj hat kaum Investitionskosten, um große Rechenzentren zu finanzieren und zu betreiben. Denn die Rechenzentren sind verteilt bei vielen kleinen Storagenode-Providern (in der Regel Privatpersonen). Daher ist das Pricing-Modell konkurrenzlos günstig. - Storj ist performant(er)!
Da die Datensegmente von vielen verschiedenen Storagenodes parallel geladen werden, kann auch die Bandbreite der tendenziell eigentlich schwachen Hausanschlüsse, hinter denen sich die meisten Storagenodes befinden, aggregiert werden. Das Ergebnis ist oft schneller als von herkömmlichen Rechenzentren. - Storj ist Open Source
Gesammelte FAQs zu Storj
Kann ich Storagenodes mit SMR-Festplatten betreiben?
Ja, das geht, sollte man aber wenn möglichst unterlassen. Festplatten mit SMR-Technik sind wesentlich langsamer als ihre Pendants beispielsweise mit PMR-Technik. Durch viele Dateizugriffe, die rein von der Betriebsweise her bei einem Storagenode entstehen, wird der Node maßgeblich ausgebremst. Dieser Effekt wird dadurch verstärkt, dass Storagenodes mit einer SQLite-Datenbank auf filebasis arbeiten – die Datenbank erzeugt dadurch zusätzliche Last auf dem Dateisystem. Das geht soweit, dass bei einer Überlastung die Datenbank des Storagenodes geblockt werden kann, was zu massiven Problemen bis hin zur Disqualification des Nodes führen kann.
Tipp: Mein erster Node läuft auf einer SMR-Festplatte und hatte genau die beschriebenen Probleme. Trotzdem möchte ich den überschüssigen Speicher gerne nutzen. Seit kurzem kann man mit einem Parameter in der docker-compose.yml die Lokation der Datenbank ändern. Ich habe diese auf ein SSD-Volume gelegt und damit massiv Last vom Filesystem genommen. Der Node läuft nun weitgehend problemfrei.
Status eines Storagenode überprüfen
Obwohl sich Storj bzw. Tardigrade bereits im Produktivbetrieb befinden, kommt es häufig noch zu Problemen beim Betrieb von Storagenodes.
Neben dem Storagenode-Dashboard sollte man sich regelmäßig die Logs des Docker-Containers anschauen.
Das geht mit folgendem Kommando auf der Konsole:docker logs --tail 200000 containername 2>&1
Wenn man sich auf die Suche nach potentiell kritischen Problemen/Fehlern macht, sollte man die Logs nach Einträgen mit “failed” durchsuchen:sudo docker logs --tail 200000 containername 2>&1 | grep "failed"
Storj und Tardigrade/StorjDCS – Was ist das?
Ganz einfach. Storj.io und Tardigrade.io sind zwei Seiten eines großen Storage-Netzwerks.
Storj.io ist dabei das Frontend/die Webseite für Storagenodebetreiber, also die Personen, die eigenen Speicher anbieten wollen.
Tardigrade.io ist das Pendant für die Personen, die Speicher mieten wollen. Der von den Storagenodes bereitgestellte Speicher wird hier als S3-Objektspeicher weitervermietet.
Update Januar 2023: Ganz so einfach scheint es dann doch nicht gewesen zu sein 😉 Mittlerweile wird der Name “Tardigrade” nicht mehr genutzt. Das Frontend für das Angebot an S3-Speicher wird mittlerweile unter dem Namen “StorjDCS” vertrieben und entwickelt.
Wie kann ich die Logs eines Storagenodes in ein File umleiten?
Standardmäßig schreibt Dein Storagenode seine Logs in das Protokoll des jeweiligen Docker Containers. Dieses Protokoll ist in der Regel nicht persistent, das heißt, es wird bei jedem Löschen des Containers und dem anschließenden Neu-Erstellen, wie es z.B. bei einem Update des Storagenodes passiert, gelöscht.
Manchmal ist es aber sinnvoll, Logfiles aufzubewahren. Daher ist es möglich, die Logeinträge in eine Datei umzuleiten und dort persistent zu speichern.
Dafür muss man einfach den Storagenode stoppen, die config.yaml öffnen und den Eintrag log.output einkommentieren und bei der Ausgabe den Pfad (aus Sichte des Containers!) zum gewünschten Logfile eintragen. Das Logfile wird dann erstellt und gefüllt.
Die gesamte Zeile sieht dann wie folgt aus:log.output: "/app/config/node.log"
Anschließend die Änderung speichern und den Storagenode neustarten.
Wie groß ist das Netzwerk? Wie viele Storagenodes gibt es?
Eine offizielle Angabe gibt es nicht. Es gibt aber eine Plattform (https://storjnet.info/), die einige Informationen über das Storj-Netzwerk sammelt.
Aktuell sind dort (Stand Juli 2020) über 6200 aktive Storagenodes erfasst.
Update: Stand Februar 2021 sind schon über 10.000 Storagenodes aktiv.
Update: Stand Februar 2022 sind es bereits über 12.000 Nodes.
Update: Stand Januar 2023 sind es bereits über 20.000 Nodes.
Update: Stand Januar 2024 sind es bereits über 24.000 Nodes in 11.800 Subnets.
Update: Stand Januar 2025 sind es bereits über 25.700 Nodes in 11.600 Subnets.
Update: Stand Mai 2025 sind es bereits über 28.000 Nodes in 11.900 Subnets.
Fehlermeldung “ERROR: could not find an available, non-overlapping IPv4 address pool among the defaults to assign to the network”
Dieser Fehler erscheint beim Erstellen eines neuen Nodes in einem Docker-Container auf einem Synology NAS sofern man gleichzeitig eine aktive (Open)VPN-Verbindung auf dem NAS eingerichtet hat (Zum Beispiel, um sich eine zusätzliche statische IP-Adresse aufzuschalten).
Wenn dieser Fehler auftritt, einfach kurz die VPN-Verbindung trennen, den Node starten und dann die VPN-Verbindung wieder herstellen.
Was sind Ingress und Egress?
Euer Storagenode erhält Ingress- und Egress-Traffic.
Ingress ist dabei eingehender Traffic, also der Download von Daten über eure Internetverbindug zu eurem Node.
Egress ist ausgehender Traffic, also der Upload von eurem Node über eure Internetverbindung.
Bezahlt werdet ihr nur für den ausgehenden (Egress) Traffic.
Mein Storagenode erhält weniger Traffic, was ist los?
Zunächst einmal ist es vollkommen normal, dass die Trafficmuster schwanken. Je nachdem, was die Kunden an Daten herunter- oder heraufladen, schwankt auch der Traffic auf deinem Node.
Eine andere Ursache kann aber auch die Verteilung des Traffics sein.
Um die hochgeladenen Daten der Kunden möglichst breit verfügbar zu machen, werden die Daten bestmöglich über das Netzwerk verteilt. Dabei spielt auch die Geographische Lokalisierung eine Rolle.
So gibt es die Einschränkung, dass der Traffic netzwerkweit auf /24 IP-Netze verteilt wird. Sind nun mehrere Nodes in einem /24-Netz, müssen sich diese den Traffic zu gleichen Teilen teilen.
Beispiel: Wenn nun also neben deinem Node noch ein weiterer Node im gleichen /24-Netz betrieben wird, teilen sich beide Nodes den Traffic. Dein Node erhält also nur noch die Hälfte des maximal möglichen Traffics. Kommt noch ein anderer Node dazu, erhältst du nur noch ein Drittel usw.
Wie kann ich überprüfen ob es weitere Nodes in meinem /24 Netz gibt?
Theoretisch kannst Du einen Portscan in deinem /24-Netz durchführen. Das bedeutet, du scannst alle IPs in dem jeweiligen /24-Netz, ob auf dem Standardport von Storj ein Service lauscht. Das ist allerdings problematisch, da diese Technik durchaus von zwielichtigen Gestalten genutzt wird und viele Provider zumindest hellhörig werden, oder deinen Anschluss sogar blockieren könnten.
Die Einfachste Methode ist es auch hier, einfach auf storjnet.info zu schauen: http://storjnet.info/neighbors
Was ist der “Vetting”-Prozess? Wie lange dauert es, bis ein Node “gevetted” ist?
Ein neuer Node tritt zunächst in den Vetting-Prozess ein. Dieser Prozess soll sicherstellen, dass der Node und die darauf gespeicherten Daten verlässlich und performant verfügbar sind.
-> Der Vetting-Prozess ist auf ca. 30 Tage angelegt
-> Während dieser Zeit erhält der Node nur ca. 4%(!) der ansonsten möglichen Daten
-> Der Vetting-Prozess läuft einzeln pro Satellite, es kann also sein, dass man auf einem Satellite (von dem man z.B: viele Daten erhält) bereits gevetted ist, während der Prozess auf einem anderen Satellite noch läuft.
-> Um erfolgreich gevettet zu sein, benötigt der Node 100 erfolgreiche Audits des jeweiligen Satellites.
Stand Februar 2022 kann der Vetting-Prozess je nach Auslastung des Netzwerks und der Anzahl der Nodes durchaus mehrere Monate dauern (Quelle).
Wie viel kann ich mit einem Storagenode verdienen?
Schau dir dazu unbedingt meinen Storj-Earnings-Estimator an:
https://addictedtocode.de/storj/storj-calculator-how-much-can-i-earn/
Schau dir auch gerne die Statistiken meiner Nodes an.
Welches FileSystem sollte für einen Storagenode genutzt werden?
Storagenodes laufen auf Festplatten und die Daten auf Festplatten sind immer in einem Filesystem (FS) organisiert.
Für den Betrieb eines Storagenodes sollte auf ext4 (Linux) bzw. NTFS (Windows) zurückgegriffen werden.
Exfat ist explizit nicht zu empfehlen, da die Blocksize hier zu groß ist und der Storagenode beinahe das doppelte an Speicher auf der Festplatte benötigt.
Zudem sind ext4 und NTFS Filesysteme mit Journals, die das Risiko eines Datenverlustes verringern.
Update Januar 2023: Auch das btrfs-Filesystem (Linux) ist explizit nicht zu empfehlen. Ich habe damit bei größeren Nodes massive Performanceeinbußen erlebt. Das Problem scheint kein Einzelfall zu sein.
Storagenodes auf Netzlaufwerken oder -Freigaben – funktioniert das?
Nein, das ist definitiv nicht zu empfehlen. Die Versuchung ist – insbesondere bei größeren Setups natürlich groß, da mit Netzlaufwerken flexibel Speicherressourcen zugewiesen werden können.
Trotzdem: Aufgrund der verwendeten SQLite-Datenbank sind Storagenodes explizit NICHT mit SMB-Freigaben oder NFS-Freigaben kompatibel. Wenn man hier einen Node laufen lässt, riskiert man, dass dieser Disqualified wird.
Selbst wenn der Betrieb glattlaufen sollte, sind Netzlaufwerke so langsam, dass dein Node viele Races verlieren wird und merklich weniger Einnahmen generieren wird, als eigentlich möglich.
Das einzige netzwerkbasierte System, das für den Betrieb eines Storagenodes verlässlich funktioniert ist iSCSi.
Storagenodes mit IPs aus verschiedenen Ländern/Erdteilen – lohnt sich das?
Nein. Ich habe es selbst versucht. Meine Hypothese ist gewesen, dass Traffic von einzelnen Kontinenten bevorzugt auf Nodes aus dem gleichen geographischen Umfeld gespeichert werden, um eine bessere Latenz und höhere Geschwindigkeiten zu erreichen.
Ich habe daher verschiedene IPs aus Amerika und Südkorea mittels VPN an meine lokal betriebenen Nodes gebunden.
Ich konnte keine andere Trafficverteilung auf den Nodes feststellen. Im Gegenteil: Aufgrund der weiten geographischen Entfernung, haben meine Nodes viel mehre “Rennen” verloren und konnten nicht rechtzeitig antworten. Das Resultat: Weniger Traffic und weniger Verdienst.
Kann ich mehrere Storagenodes unter einer IP bzw. in einem /24 IP-Netz vetten?
Der Traffic je /24-IP Netz ist aufgeteilt: Ca. 95% des Traffics gehen an gevettete Nodes und 5% gehen an Nodes, die sich im Vetting-Prozess befinden.
Demnach ist es kein Problem, einen neuen Storagenode im gleichen /24-Netzwerk wie ein bereits fertig gevetteten Node laufen und vetten zu lassen.
Der Prozess des Vettings verlangsamt sich erst, wenn 2 oder mehr Nodes, die aktuell im Vetting-Prozess sind, sich in einem /24-Netz befinden, da diese sich dann die 5% Vetting-Traffic teilen müssen.
Storj-Nodes und Steuern
Achtung: Die folgenden Zeilen sind nur meine persönliche Herangehensweise und KEINE steuerliche Beratung, da ich diese weder geben kann noch darf!
Spätestens bei mehreren Nodes stellt sich in Deutschland schnell die Frage nach der Besteuerung der Storj-Einnahmen. Ich betrachte die Storj-Vergütung als Einnahmen und gebe diese in meiner Einkommensteuererklärung an. Dafür habe ich ein Gewerbe angemeldet und führe die Vergütung in EURO zum jeweiligen Zeitpunkt der Überweisung der STORJ-Token nach dem aktuellen Wechselkurs an. Diesen Betrag gebe ich dann als Einnahme in meiner EÜR an. Mein Finanzamt hat das bisher immer so akzeptiert.
Quellen und weitere Ressourcen:
– https://forum.storj.io/
– https://www.synology-forum.de/threads/storj-speicher-vermieten.92657/
– Storj-Whitepaper
Wolfgang
Hi, toller Beitrag. Ich ich hatte erst SMR Platten in Betrieb. Die habe ich dann wegen der schlechten Node-Performance rausgehauen und CMR Platten verwendet. Läuft seither deutlich besser.
Du könntest vielleicht etwas zu den Stromkosten sagen. Meine DS218+ hatte damals ca. 3,5€ Stromkosten im Monat und meine DS418play hat jetzt ca. 7€. Das ist vielleicht für jemand interessant, der die DS nicht eh schon in Verwendung hat und sie nur für den Storj anschafft.
Ich verdiene aktuell mit meinem Knoten ca. 2,5€/TB/mnt. Eine HDD kostet aktuell 27-29€/TB. Die Investition einer Platte ist also nach etwas mehr als einem jahr wieder drin. Dann sollte man noch die NAS Kosten einrechnen und davon ausgehen, dass eine Platte in diesem Dauerbetrieb nach 3-4 Jahren hinüber ist.
Trotzdem wird (zu recht) von einem Raid Verbund abgeraten und bei Verlust das Aufsetzen eines neuen Knotens empfohlen.
Jan-Dirk
Hallo Wolfgang!
Danke für Deine Anmerkungen 🙂
zu 1)
Danke für den Tipp!
Ich hatte auch größere Probleme (unter anderem mit gelockten Datenbank-Files und Co) mit einer SMR-Platte gehabt. Seit einer der letzten Versionen kann man die Datenbank-Location in der Config anpassen.
Ich habe daraufhin die Datenbank auf ein SSD-Volume gelegt und jetzt rennt der Node wesentlich schneller (Ich werde dazu auch nochmal einen Artikel schreiben). Trotzdem ist die SMR-Platte noch immer am Anschlag. Aber naja, ich habe sie halt noch rumliegen 😉
zu 2)
Eine gute Idee, die Stromkosten werde ich noch mit aufschlüsseln. Wobei der Vergleich dann ein wenig hinkt, da die DS ohnehin 24/7 läuft und nicht ausschließlich für Storagenodes genutzt wird. Ich denke bis man da in den Bereich der Wirtschaftlichkeit kommen würde, würde es lange dauern.
zu 3)
Das ist spannend! Ich werde die Tabelle mal um die Auflistung “Verdienst pro TB” ergänzen.
Als Tipp: Oftmals gibt es schon HDDs für bis zu 16€/TB im Angebot. Sind zugegebenermaßen aber in der Regel SMR-Consumer-HDDs.
zu 4)
Hier bin ich komplett bei Dir. Das Storj-Netzwerk ist ja auf Redundanz ausgelegt. Also kann das Netzwerk den Ausfall eines Nodes verkraften. Da nutze ich lieber jede HDD einzeln und maximiere den Gewinn 😉
Gruß
Jan-Dirk
Wolfgang
Super Beschreibung. Ich stehe nun vor der Herausforderung, ein zweites Node (Speicherort auf einer USB-HDD) anzulegen und möchte mein erstes node nicht gefährden. Meine Frage richtet sich damit an das Vorgehen:
Nochmals muss ich ja vermutlich nicht das Docker-Image downloaden, da ja bereits vorhanden. Liege ich daher richtig, dass ich einfach per Befehl ein zweites Node starte?
Wenn ja:
docker run -d –restart unless-stopped –stop-timeout 300 \
-p 28967:28967 \
-p 127.0.0.1:14003:14002 \
-e WALLET=”0xXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX” \
-e EMAIL=”user@example.com” \
-e ADDRESS=”domain.ddns.net:28967″ \
-e STORAGE=”2TB” \
–mount type=bind,source=””,destination=/app/identity \
–mount type=bind,source=””,destination=/app/config \
–name storagenode-usb storjlabs/storagenode:latest
Also nur auf 14003 abändern und 28967 belassen?
Würde die letzte Zeile passen?
–> name storagenode-usb storjlabs/storagenode:latest
Viele Fragen 🙂 Danke schonmal vorab und noch einen schönen Tag.
Jan-Dirk
Hallo Wolfgang,
bitte entschuldige, ich habe Dein Kommentar erst jetzt gesehen 🙁
Ich werde in Kürze einen Artikel schreiben, wie man mehrere Nodes auf einem System (z.B. Synology-NAS) mittels Docker betreibt, ohne dabei seine bisherigen Nodes zu gefährden.
Da es durchaus Vorteile hat, mehrere Nodes zu betreiben ist das durchaus sinnvoll 😉
Nun aber – auch wenn Du schon die Lösung gefunden hast – zu Deiner Frage:
Du hast vollkommen Recht, dass das Docker-Image bereits geladen ist, du musst es nicht mehrmals herunterladen, es kann nach dem ersten Download für beliebig viele Instanzen genutzt werden.
Du musst also nur in der Docker-Compose ein paar Werte anpassen:
1.) Ein anderer Containername
2.) Angepasste Verzeichnisse für die neue Identity (pro Node ist unbedingt eine neue Identity notwendig!)
3.) Das Datenverzeichnis anpassen
4.) Die Ports anpassen.
Bei den Ports musst Du beide Ports, also sowohl den für das Dashboard (14002), als auch den für den Service (28967) anpassen.
Anzupassen ist jeweils nur der externe Port, der interne Port des Containers bleibt beim Standard, damit der Node lauffähig ist.
Das sieht dann in der docker-compose so aus:
14003:14002
bzw.
29868:29867
Also vor dem Doppelpunkt der (neue) externe Port und hinter dem Doppelpunkt der interne Port.
Achtung, bei der Angabe der Adresse des Nodes musst Du dann auch den neuen Port angeben:
-e ADRESS=”domain.ddns.net:28968″
PS: Nicht vergessen, die Ports für den neuen Node ebenfalls in der Firewall/im Router freigeben.
Beste Grüße aus Bielefeld
Jan-Dirk
Wolfgang
Hat sich erübrigt. Lösung ist gefunden
Marijus
Hallo,
sollte ich einige an Storj Tokens verdient heben, wie kann ich die in Euros umwandeln und in Bankkonto oder Paypal überweisen? Hast du schon gemacht?
Viele Grüße
Marijus
Jan-Dirk
Hallo Marijus,
ja, das geht (ist leider nicht ganz so trivial wie eine Paypal-Überweisung).
Storj-Tokens, die du als Vergütung erhältst sind sog. “ERC20-Tokens”, die auf der Ethereum-Blockchain transferiert werden.
Das bedeutet, wenn du coins transferieren und/oder auszahlen lassen willst, benötigst du leider immer ein klein wenig ETH-Coins.
Um Storj-Coins auszuzahlen, kannst du deine Coins an jede beliebige Crypto-Börse überweisen, diese dort verkaufen (z.B. in USD oder EUR) und dann an dein Bankkonto überweisen lassen.
Ich habe hier gute Erfahrungen mit der Börse “kraken.com” gemacht. Dort kannst Du Storj gegen Euro verkaufen und dann auf dein Bankkonto auszahlen lassen.
Beste Grüße aus Bielefeld
Jan-Dirk
Marijus Luinys
Danke für deine Antwort. Da ich noch nie sowas gemacht habe, fühle ich mich dabei nicht sicher. Meine storj’s liegen auf myetherwallet.com. Soweit ich verstehe, muss ich diese auf kraken.com überweisen um in EUR konvertieren zu können. Um eine solche eine Überweisung zu machen brauche ich etwa 0,02 ETH (max?). Damit storj’s an kraken ankommen, muss ich dort storj-Deposit haben. Beim Erstellen des Deposit’s, die Seite sagt “Deposit Storj by sending to a deposit address shown below. Click “Generate New Address” to generate one if none appear.
Use the Storj transfer method with your deposit address as destination to deposit tokens into your Kraken account.
Because addresses expire, if you create more than 5 addresses, then the oldest ones will be set to expire in 7 days until you have 5 addresses again.
Use the available buttons to copy the address to your wallet. Choose Select to paste to your wallet or use the QR Code to scan to your wallet.
30 confirmations are required before the funds are available for trading.
Minimum
⬡10.00000
Fee
⬡1.00000
Address Setup Fee
⬡1.00000″
Bedeutet daß ich 30 Überweisungen machen muss damit ich auf Kraken mit storj’s handeln kann? So was würde gesamtes Profit deutlich mindern. Und es ist mir nicht wirklich verständlich wie mache ich solche Überweisung vom myetherwallet (oder lieber eine andere Seite nutzen?). Dort gibt’s irgendwelche stakes, exchange, swaping… Wie macht man das Ganze am besten und am schnellsten?
Viele Grüße
Marijus
Melanie
Ja ich stehe vor dem gleichen Problem. Was bedeutet das mit den 30 conformations?
Daniel
Danke für die Anleitung leider klappt das bei mir nicht. Bekomme folgenden Fehler:
ERROR contact:service ping satellite failed {“Satellite ID”: “xxxxxxxxxx”, “attempts”: 7, “error”: “ping satellite error: failed to dial storage node (ID: xxxxxxxxxx) at address daschmidt.ddns.net:28967: rpc: dial tcp 193.83.117.10:28967: i/o timeout”, “errorVerbose”: “ping satellite error: failed to dial storage node (ID: xxxxxxx) at address dxxxxxxx.net:28967: rpc: dial tcp xxxxxxxxx:28967: i/o timeout\n\tstorj.io/storj/storagenode/contact.(*Service).pingSatelliteOnce:141\n\tstorj.io/storj/storagenode/contact.(*Service).pingSatellite:95\n\tstorj.io/storj/storagenode/contact.(*Chore).updateCycles.func1:87\n\tstorj.io/common/sync2.(*Cycle).Run:92\n\tstorj.io/common/sync2.(*Cycle).Start.func1:71\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57”}
kann mir hier jemand weiterhelfen.
MFG Schmidt
Jan-Dirk
Hallo Daniel,
der Fehler sieht zunächst schlimmer aus, als er eigentlich ist.
Im Prinzip sagt er nichts anderes aus, als dass dein Node den Satellite nicht erreichen kann bzw. der Sattelite deinen Node nicht erreichen kann.
Wenn dieser Zustand länger anhält, wird dein Node zunächst suspendiert (Suspension) und später Disqualifiziert.
In den meisten Fällen liegen diese Verbindungsprobleme an Routern oder Firewalls, bei denen der entsprechende Port (in deinem Fall 28967) geblockt bzw. nicht an den Rechner mit dem Node weitergeleitet wird.
ein anderer Ansatzpunkt wäre, dass deine dyndns-Domain nicht auf die aktuelle IP deines Anschlusses geupdated war/ist.
Beste Grüße
Jan-Dirk
Jens
Hallo,
super Anleitung und die Einrichtung hat bei mir auch super geklappt.
Kurze Frage zu dem Wallet.
Ich habe bei Coinbase ja die Möglichkeit ein “STORJ” Wallet oder ein “ETH” Wallet zu nutzen. Welches Wallet gebe ich in der Storagenode an?
Grüße
Jens
Stefan
Hallo,
super Anleitung, danke dafür! Benötigt man für jedes Node eine eigene Mail-Adresse?
Gruß
Stefan
Jan-Dirk
Hallo Stefan,
Ja, man benötigt jeweils eine eigene E-Mail-Adresse pro Node.
Beste Grüße